Transformation of Applications to Docker way of implementations is taking the hold with most of the domains to most effective usage of the resources and for a better Micro Service Management Strategy.
Docker as a Engine which operates as the light weighted container Hypervisor needs a helping hand with some of the tools which solves most of the orchestration and clustering problems which one eventually try to create a loop of servers on a single click.
Seeing that Issue Docker have created some magical tools around which gives solutions to some of the problems which can solve the Orchestration and Clustering of the Docker Containers across the Cloud Providers or any Hybrid Cloud Model.
Lets start the Fight

Docker {Machine}
Docker Machine is a tool which helps you provision servers on multiple cloud providers to install docker and give you the access to these machines over tcp port which the docker runs which exposes it api.
How to download Docker-Machine
Linux and Other Distros
$ curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_darwin-amd64 > /usr/local/bin/docker-machine
$ chmod +x /usr/local/bin/docker-machine
Windows
curl -L https://github.com/docker/machine/releases/download/v0.2.0/docker-machine_windows-amd64.exe > /usr/local/bin/docker-machine
How to run
I use Cygwin on my machine to make use of the Linux based functionalities on the machine easily,so i saved the docker-machine.exe in the /usr/local/bin/docker-machine
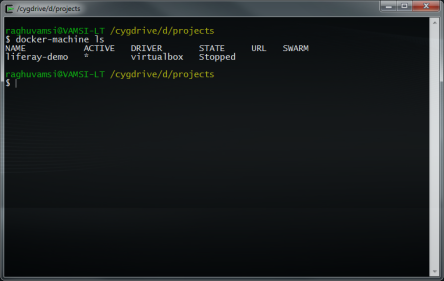
so after that we need to create a instance on a aws and docker-machine comes up with most of the Cloud providers integration like IBM Softlayer,DigitalOcean,Rackspace and AWS and also with some of the private cloud providers like Openstack,Vmvspehere.
So Lets create a instance on AWS
On a Special Note is that Docker have release there Windows client where we can connect to the docker instances with their api.
You can download it from the Windows Package manager Chocolatey.
Before creating the instance make sure to understand on what options are available to create on aws
--amazonec2-access-key AWS Access Key [$AWS_ACCESS_KEY_ID]
--amazonec2-ami AWS machine image [$AWS_AMI]
--amazonec2-iam-instance-profile AWS IAM Instance Profile
--amazonec2-instance-type "t2.micro" AWS instance type [$AWS_INSTANCE_TYPE]
--amazonec2-region "us-east-1" AWS region [$AWS_DEFAULT_REGION]
--amazonec2-root-size "16" AWS root disk size (in GB) [$AWS_ROOT_SIZE]
--amazonec2-secret-key AWS Secret Key [$AWS_SECRET_ACCESS_KEY]
--amazonec2-security-group "docker-machine" AWS VPC security group [$AWS_SECURITY_GROUP]
--amazonec2-session-token AWS Session Token [$AWS_SESSION_TOKEN]
--amazonec2-subnet-id AWS VPC subnet id [$AWS_SUBNET_ID]
--amazonec2-vpc-id AWS VPC id [$AWS_VPC_ID]
--amazonec2-zone "a" AWS zone for instance (i.e. a,b,c,d,e) [$AWS_ZONE]
So lets export the AWS Accesskey and Secretkey
export AWS_ACCESSKEY={your own aws account accesskey}
exprt AWS_SECRETKEY={your own aws account secretkey}
Creating the Instance on AWS
docker-machine create -d amazonec2 --amazonec2-access-key $AWS_ACCESSKEY \
--amazonec2-secret-key $AWS_SECRETKEY \
--amazonec2-instance-type "t2.medium" \
--amazonec2-region "us-east-1" \
--amazonec2-vpc-id "vpc-8e3317eb" \
--amazonec2-subnet-id "subnet-61106116" Demo123
Instance creation may take some time to do lot more magical stuff to provision you the instance with a running docker on top of it.After creating the instance lets see if we can see it in the list of instances from docker-machine output.
raghuvamsi@VAMSI-LT /cygdrive/d/projects
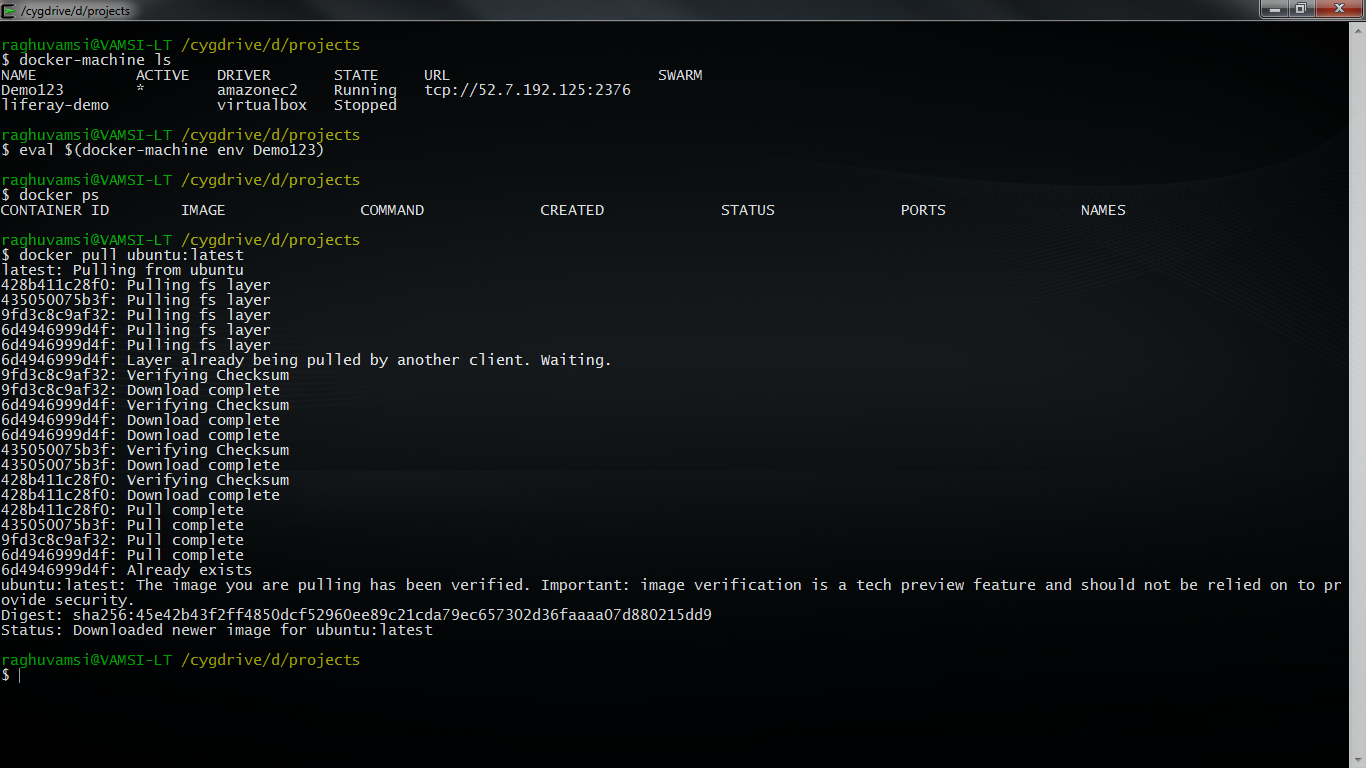
$ docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM
Demo123 * amazonec2 Running tcp://52.7.192.125:2376
liferay-demo virtualbox Stopped
Now lets check connecting to the instance .If you are running on a CYGWIN based environment then we need to run this command
eval $(docker-machine env Demo123)
So now lets check it with the docker command and see whether we can run some of the docker commands
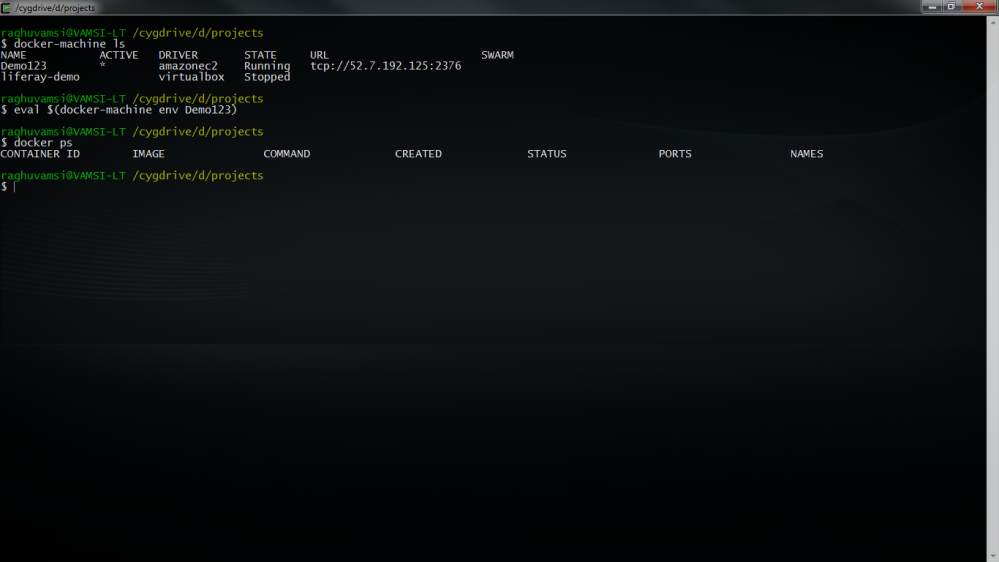
Now lets pull some images on this Machine
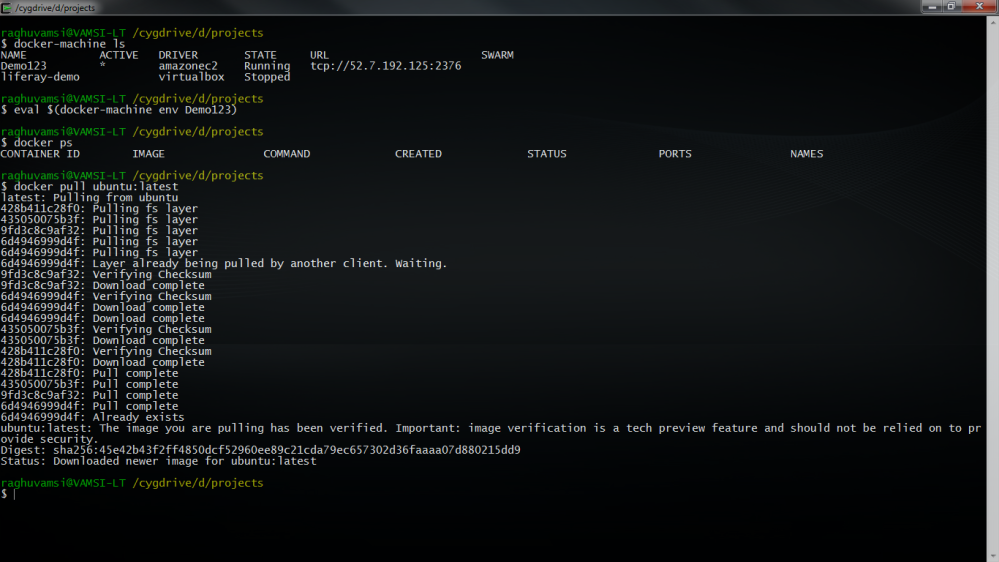
We have pulled ubuntu image on this machine
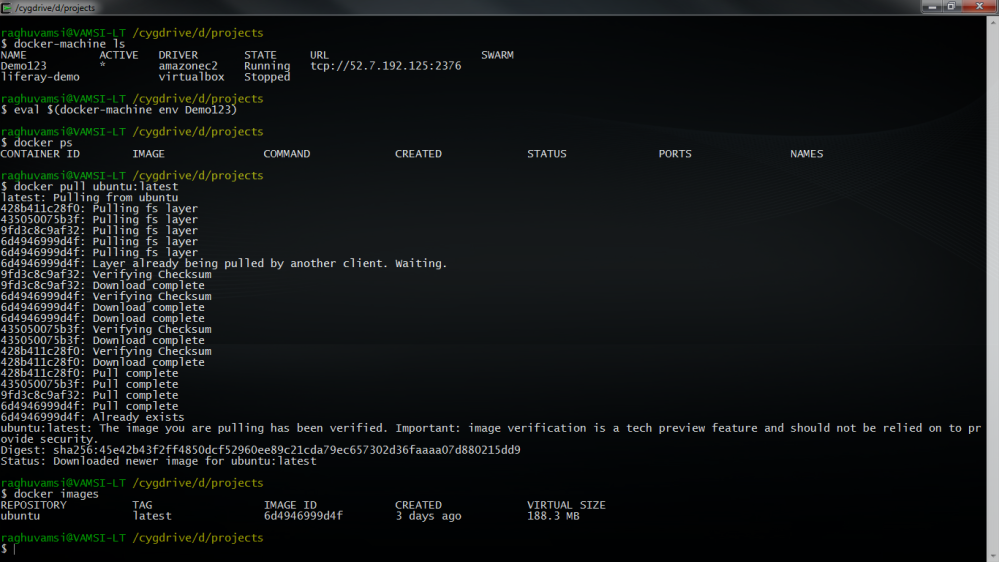
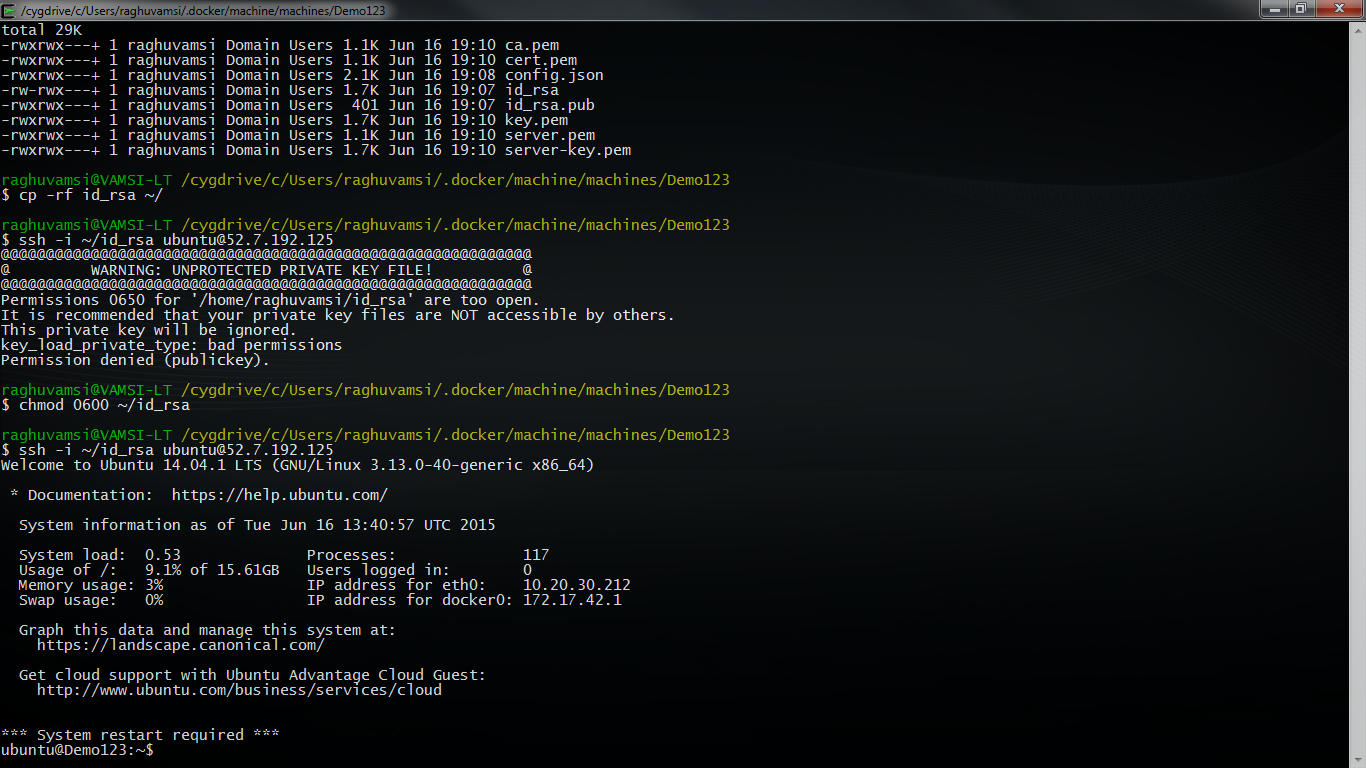
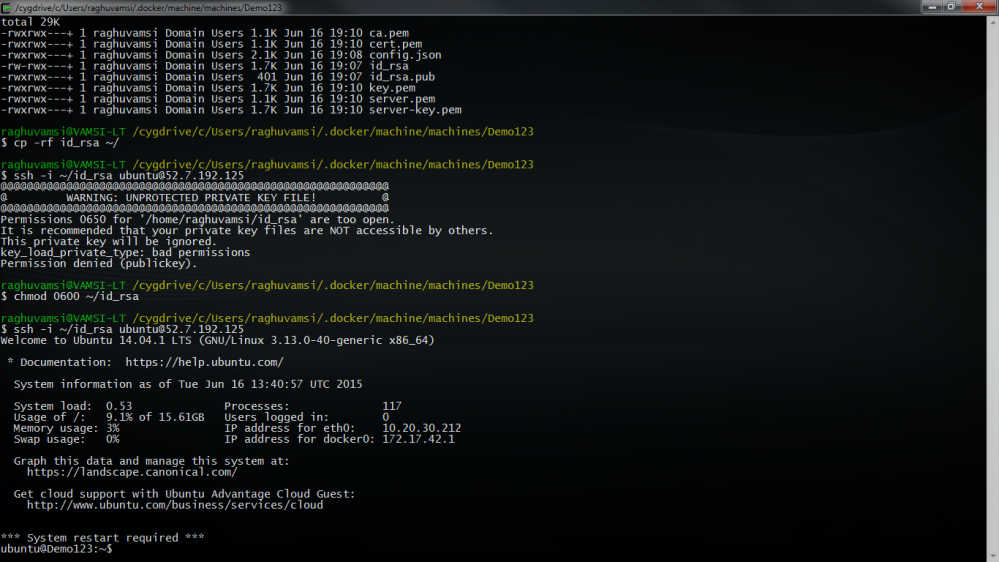
And now we can run all the docker commands on this pc.If you would like to login to this machine you need to use the pem key created for this machine at ~/$USER_HOME/.docker/machine/machines/$MACHINE_NAME/id_rsa
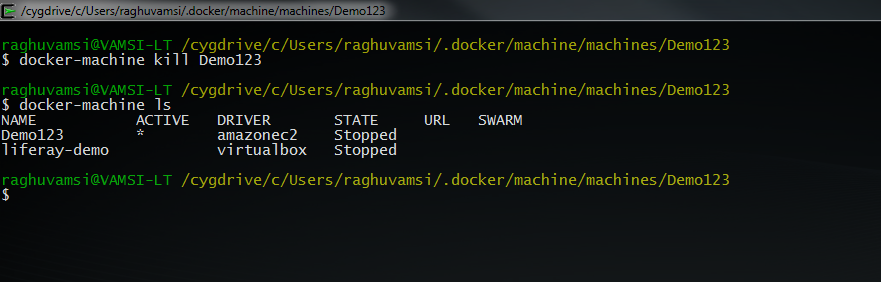
I will kill or destroy this machine with the following command
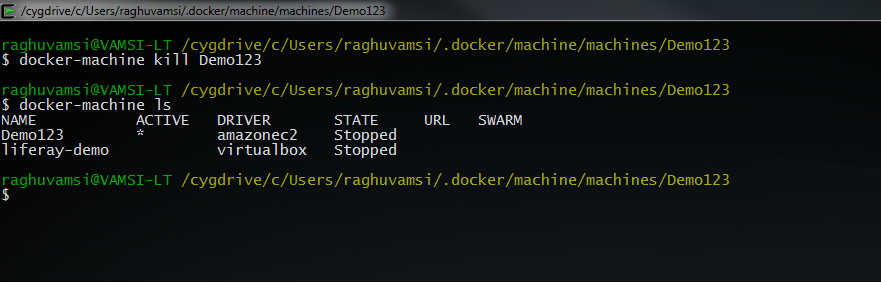
Docker-machine comes with some more commands to inspect the instance and check its version with
docker-machine inspect Demo123 -> Inspect information about a machine
docker-machine config Demo123 -> Print the connection config for machine
Stay Tuned for the Second part of it on how we integrate a Swarm Cluster with multiple Instances across regions on AWS